Since about a month ago my Asterisk cluster became very unstable.
Initially Asterisk was crashing with SEGFAULT. We found a work around after opening this issue.
The work around is described there and involved using IP instead of a hostname on the PJSIP trunk configuration as the DNS resolution was taking too long.
After that we didn’t experience more crashes but some calls started being rejected. I don’t know if this started after we fixed the crash or at the same time the crash started but it was not present before these problems started.
The most common rejected call flow is shown here:
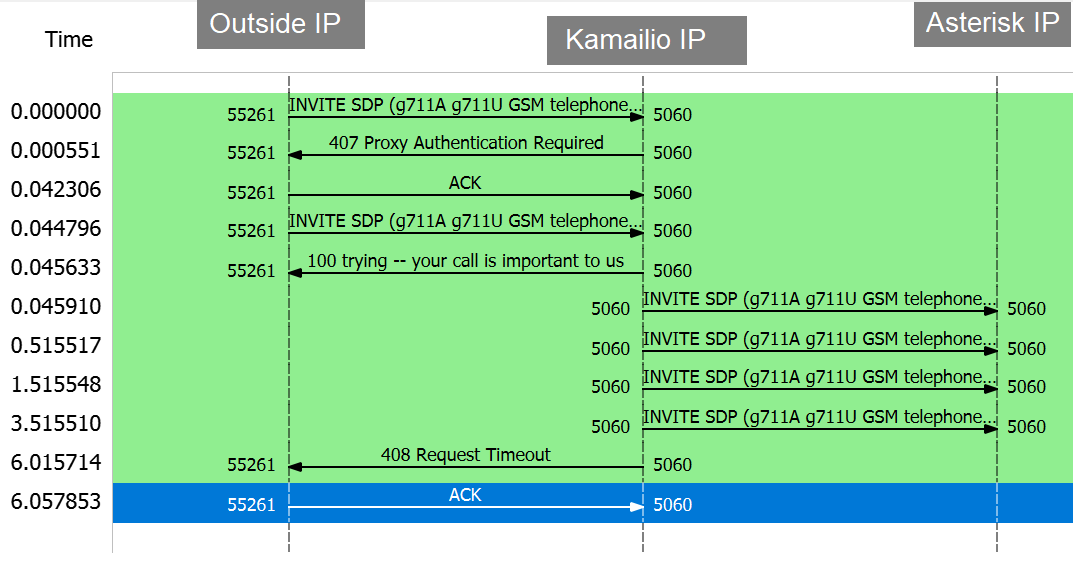
Sometimes Asterisk will actually answer but it will be too late, as shown here:
IMAGE ON NEXT POST DUE TO FORUM RESTRICTIONS (IMAGE 2)
These were taken after we increased the invite timeout on Kamailio to 6s, up from 3s. It mitigated some of rejected calls. I don’t feel that increasing it further is the best way to go.
On Askterisk PJSIP logs I can see the invites being received as shown here. (This log was taken before the timeout increase to 6s)
I noticed that the thread that processes the response didn’t print any logs for several seconds. In the example linked above the thread had this log:
[Aug 18 15:55:31] VERBOSE[121143] res_pjsip_logger.c: <--- Transmitting SIP response (560 bytes) to UDP:<KAMAILIO IP>:5060 --->
Then these:
[Aug 18 15:55:37] VERBOSE[121143] pbx_variables.c: Setting global variable 'SIPDOMAIN' to '<ASTERISK IP>'
[Aug 18 15:55:37] VERBOSE[121143] res_pjsip_logger.c: <--- Transmitting SIP response (560 bytes) to UDP:<KAMAILIO IP>:5060 ---> //This is the first reply we see from the logs linked above
In between these, I can see other threads replying to other SIP messages.
CONTINUING ON NEXT POST DUE TO FORUM RESTRICTIONS
EDITED TO UNFLAG. Not sure why this was flagged.
